
There are seven possible types of high-level outcomes attribution evaluation designs. These are described below. In each case, diagrams are used to illustrate the designs so as to assist cross-discipline clarity regarding what a particular type of design actually entails. It is hoped that over time, this set of designs (amended if necessarily) can provide an exhaustive and mutually exclusive set of designs such than any evaluation can unambiguously be identified as using one or more of these designs [1]. At the moment these designs are specified using language used in evaluation and policy analysis, in future they may be specified in more generic language which includes the way in which such designs are seen in econometrics and other disciplines.

True experimental design
In the typical simplest case of this design, a group of units (people, schools, hospitals) is identified which is the focus of the intervention being studied. A sample is taken from this group (if there are large numbers of the particular unit on which the intervention could be used). The sample is randomly divided. One half of the units have the intervention applied to them (the intervention group) and the other half do not (control group). Changes in measurements of the high-level outcomes are compared before and after the intervention has been run. It is presumed that any significant difference (beyond what is estimated as likely to have occurred by chance), is a result of the intervention. This is because there is no reason to believe that the units in the intervention and the control group differed in any systematic way which could have created the difference, apart from receiving, or not receiving, the intervention. The diagram below illustrates this.

Regression discontinuity design
A regression discontinuity design can be used in the
case where units can be ranked in order based on measurement of a high-level
outcome before any intervention takes place. For instance, reading level for students or crime clearance
rate for a police district. A
sub-set of the units below a point on the outcome measurement are then given
the intervention. After the
intervention has taken place, if it is successful, there should be a clear
improvement in those subject to the intervention but no similar amount of
improvement amongst those units above the cut off point (which did not receive
the intervention). This design is
more ethically acceptable in a case where there are limited resources for
piloting an intervention because (in contrast to a true experiment) the
intervention resources are being allocated to those units with the greatest
need.
The diagram below represents this design.

Time series design
A time series design uses the fact that a sufficiently long series of measures have been taken on a high-level outcome. An intervention is then introduced (or has been introduced in a retrospective analysis) and if the intervention has had an effect, a clear shift in the level of the high-level outcome measurements should be observable at the point in time when the intervention occurred.
The diagram below sets this out.

Exhaustive alternative causal explanation elimination design
The exhaustive alternative causal explanation design proceeds by examining all of the possible alternative hypothetical outcomes hierarchies that may lie behind the changes observed in high-level outcome measurement. This can use a range of techniques all directed at identifying and excluding alternative explanations to the intervention. Sometimes this is described as more “forensic-type” method rather than the experimental approaches used above.
The diagram below sets this out.

Expert opinion summary judgment design [1]
In this design, an expert is asked to give their summary judgment opinion regarding whether high-level outcomes are attributable to an intervention. They are expected to use whatever data gathering and analysis methods they normally use in their work in the area and to draw on their previous knowledge in dealing with similar instances.
The diagram below sets out this design.

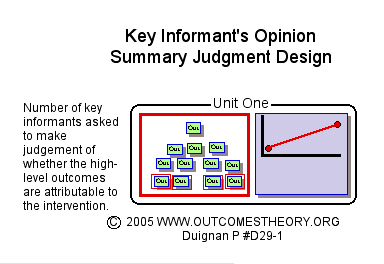
Key informants opinion summary judgment design [1]
In this design, key informants (people who have experience of the program or significant parts of the program) are asked to give them summary judgment opinion as to whether changes in high-level outcomes are attributable to the intervention. They are expected to use whatever data gathering and analysis methods they normally use in their day to day work and to draw on their previous knowledge in dealing with similar instances. These judgments are then summarized and analyzed and brought together as a set of findings about the outcomes of the program. [2]
[1] The first five of these designs are based on the thinking of the international evaluation expert Michael Scriven on possible ways of establishing causality in evaluation. The author has added the final two as some stakeholders in some situations regard these as providing sufficient evidence of causality for them to act upon. Whether or not these designs are accepted by a particular community of users of an outcomes system is up to that community of users. In theory it would be possible for a community of users to reject the notion that there are a particular set of whole-intervention outcomes attribution evaluation designs which provide more robust outcome attribution than other types of evaluation (often known as formative or process evaluation). Some of those who adopt a post-modern, relativist, interpretativist or constructivist theory of science may want to do so. Outcomes theory only seeks that such communities of users make an explicit decision about their rejection so that they can be clear about what is known, not known and what is feasible and affordable to know about a particular outcomes system.
[2] A number of communities of users believe that the last two designs would not usually be expected to establish causality as robustly as the other listed designs. However these designs are frequently used by some communities of users and therefore deserve a place in a full typology of whole-intervention outcome attribution evaluation designs; in particular circumstances they are feasible, timely, affordable and accepted by stakeholders as better than having no whole-intervention high-level outcome attribution information. Even though they are often more feasible, timely and affordable than the other five designs, decision-makers have to consider on a case by case basis whether these designs can actually provide any coherent information about attribution or whether they will just end up being examples of pseudo-outcomes studies. Pseudo-outcomes studies are ones which do not contribute any sound information about attribution to a particular intervention but merely record that outcomes improved over the time period that the intervention was running.
V1-0.